Splitting a document
You can split a document into multiple parts using the Documents Plugin. This feature is useful, for example, when a user uploads a bulk scanned file that needs to be separated into separate files.
Sending the request
To split a document, follow these steps:
- Create a process and add a Kafka send event node and a Kafka receive event node. These nodes are used to send the request and receive the reply.
- Configure the first node, Kafka send event node by adding a Kafka send action.

- Specify the Kafka topic to which you want to send the request.
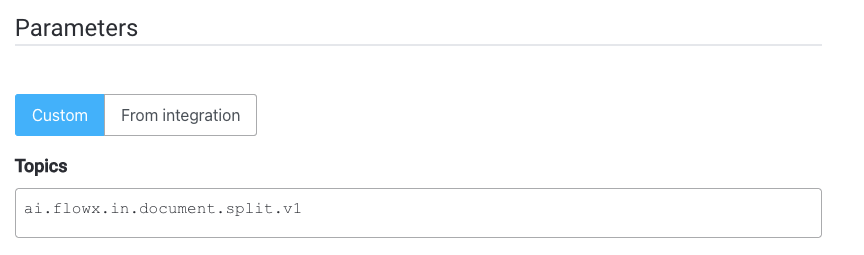
- Fill in the body message request:

- fileId: The ID of the file to be split.
- parts: A list containing information about the expected document parts.
- documentType: The document type.
- customId: The client ID.
- shouldOverride: A boolean value (true or false) indicating whether to override an existing document if one with the same name already exists.
- pagesNo: The pages that you want to separate from the document.
You can customize the Kafka topic names by overwriting the following environment variables during deployment:
KAFKA_TOPIC_DOCUMENT_SPLIT_IN - default value: ai.flowx.in.qa.document.split.v1 - this is the topic that listens for the request from the engine
KAFKA_TOPIC_DOCUMENT_SPLIT_OUT - default value: ai.flowx.updates.qa.document.split.v1 - this is the topic on which the engine expects the reply
The above examples of topics are extracted from an internal testing environment. When setting topics for other environments, follow this pattern: ai.flowx.updates.{{environment}}.document.split.v1.
The Engine listens for messages on topics with specific names. Make sure to use an outgoing topic name that matches the pattern configured in the Engine.
Receiving the reply
You can view the response by accessing the Audit log menu. The reply will be sent to the Kafka topic specified in the Kafka receive event node.

The response body will contain the following values:
- docs: A list of documents.
- customId: The client ID.
- fileId: The ID of the file.
- documentType: The document type.
- minioPath: The storage path for the document.
- downloadPath: The download path for the document.
- noOfPages: The number of pages in the document.

Here's an example of the response JSON:
{
"docs": [
{
"customId": "1234_759769",
"fileId": 4743,
"documentType": "BULK",
"documentLabel": null,
"minioPath": "qualitance-dev-paperflow-qa-process-id-759770/1234_759769/4743_BULK.pdf",
"downloadPath": "internal/files/4743/download",
"noOfPages": 2,
"error": null
}
],
"error": null
}